


“Irrelevant. I am a drone. Drones do not have feelings.” “Then how do you know you’re not curious?” — Data and Seven of Nine, Star Trek: Voyager (fan fiction, but you get the idea)
Knowledge is power. It’s practically a cliché. Francis Bacon said it, Schoolhouse Rock sang about it, and every consultant who’s ever charged $500/hour has put it in a deck. But here’s something that snuck up on me over the past few months: your AI team needs a strategy for it just as much as you do.
In Part 4, I showed you how I turned a squad of AI agents into a distributed system that could survive machine reboots, race conditions, and the particular humiliation of 37 consecutive failures on a Sunday afternoon. That post was about making the squad reliable.
This one is about making it smarter.
Because here’s the thing. An agent that gets restarted every morning with zero memory is just an expensive autocomplete. The magic only happens when the squad accumulates knowledge faster than it forgets it — when every problem it solves makes the next one easier. Compounding knowledge. That’s the goal. And getting there turned out to involve a researcher agent, a daily newspaper, something called reflection, and eventually an entirely separate squad with a completely different personality.
Meet Seven
Every good team has that one person who has read absolutely everything. Who can pull up a reference on any topic at a moment’s notice. Who quietly noticed the pattern everyone else missed and calmly mentioned it two weeks before it became a crisis.
On my squad, that’s Seven.
Seven of Nine — Research & Docs — has been on the roster since day one, quietly doing the work that nobody notices until it’s not there. She tracks architecture decisions, writes the documentation that actually matches the code (a miracle in any organization), and maintains the squad’s institutional memory through .squad/decisions.md and her own running history file.
But her real superpower showed up slowly, over months of watching her work. Seven doesn’t just document things. She synthesizes them. When I asked her to research the best approach for cross-machine agent coordination (this was before Part 4’s chaos), she didn’t just Google it. She pulled five competing approaches, ran them against our actual constraints, assigned confidence levels to each finding, and delivered a recommendation with full reasoning attached. The research report was better than anything I would have written myself.
That experience changed how I thought about the squad’s knowledge pipeline. Documentation is the output. Research is the input. We’d invested heavily in the output side — decisions.md, skill files, history logs — but the input side was still mostly me, doing research when I happened to remember to do it.
Time to fix that.
The Squad Gets a Newspaper
The problem with staying current in tech is that it requires relentless, deliberate attention that I don’t reliably have. My “I’ll read this later” folder is where articles go to die. My browser tabs are a monument to good intentions.
So I gave the job to Neelix.
Neelix is the squad’s news reporter — think of him as the ship’s morale officer crossed with an anchor desk. Witty, energetic, and genuinely committed to making sure I actually read the updates instead of closing the notification. The addition of tech news scanning was, in retrospect, a natural extension of what he was already doing for squad status updates.
The setup was straightforward: Neelix now runs a daily scan of HackerNews (top stories + trending 24h) and Reddit (r/programming, r/devops, r/kubernetes). Stories that hit relevance thresholds — AI tooling, Kubernetes, security vulnerabilities, developer productivity — get filtered, ranked, and formatted into a styled digest that lands in my Teams channel every morning.
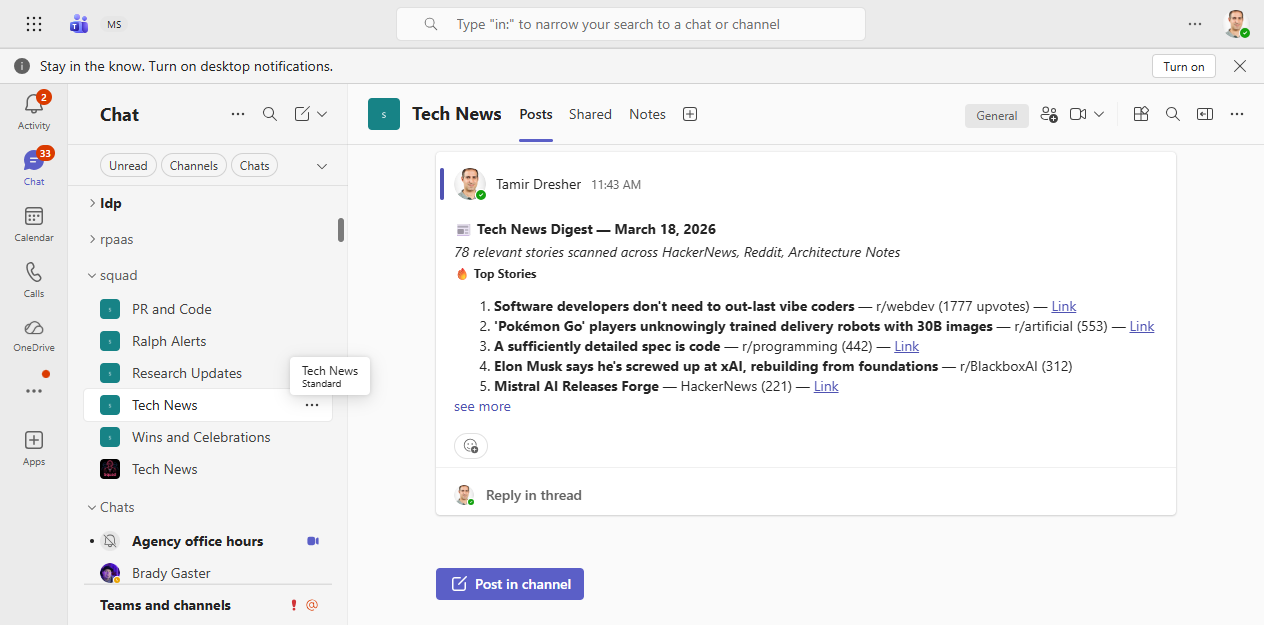 Neelix’s daily tech news digest — yours, delivered with personality
Neelix’s daily tech news digest — yours, delivered with personality
But here’s the part I didn’t expect: the news doesn’t just inform me. It informs the squad.
When a news story flags a new CVE in a dependency we use, Worf gets a task. When a new Kubernetes feature drops that changes how we should configure something, B’Elanna gets a work item. When a new AI model releases with dramatically better benchmark scores, Seven gets a research task to evaluate whether we should update agent assignments.
The squad reads the news and derives its own work from it. That’s not automation. That’s continuous learning.
Reflection: Making Mistakes Once
Here’s an embarrassing confession: for the first couple of weeks of running a squad, the agents made the same mistakes repeatedly. Not catastrophic mistakes — nothing caught fire — but the kind of low-grade recurring friction that slowly grinds you down. Agent writes docs in the wrong format. I correct it. Next session: same wrong format. I correct it again. The third time I corrected it I had the distinct feeling I was arguing with someone who had no short-term memory.
That’s because I was. Sessions end. Context resets. Without a mechanism to persist what worked and what didn’t, every conversation starts from zero.
The reflect skill changed this.
Borrowed and adapted from a pattern in Microsoft’s internal tooling (thanks to Richard Murillo’s original design), reflect is a structured system for capturing learnings from conversations and routing them to the right place in the squad’s knowledge architecture. When I correct an agent — “no, use the azure-devops MCP tool instead of raw API calls” — that correction gets classified as a HIGH confidence learning, proposed back to me for review, and if approved, written to the relevant history file or decisions.md. The agent won’t make that mistake in the next session, because the correction lives in the file it reads before every task.
The skill classifies learnings into three tiers:
- HIGH confidence: explicit corrections (“no”, “wrong”, “never do this”)
- MEDIUM confidence: praised patterns and discovered edge cases
- LOW confidence: repeated preferences that accumulate into a pattern
Anything team-wide goes through the decisions inbox, where Scribe reviews and merges it into the canonical decisions.md. Agent-specific learnings go into that agent’s history file. The knowledge is never lost in the void of a closed chat window again.
Both the reflect skill and the news-broadcasting skill have since been contributed back to the public Squad repository as community skills — the idea being that any Squad can plug in a learning capture system or a news pipeline without rebuilding from scratch. Knowledge compounds not just within a team, but across the whole ecosystem.
The Research Institute Forms
Somewhere in the second week, I noticed that Seven was doing a lot of research that had nothing to do with the main squad’s engineering work. Investigations into SaaS tool comparisons. Analysis of affiliate revenue models. Competitive landscape research for developer tools.
Not because I asked her to. But because the news pipeline was surfacing topics and the work was falling into her lap by default.
That’s when I had what I can only describe as a squad architecture epiphany: some work requires a different kind of team.
The engineering squad — Picard, Data, Worf, B’Elanna, Seven, and the rest — is optimized for building and shipping. They’re relentlessly practical. They care about PRs and CI pipelines and whether the Helm chart is correct. That’s exactly what you want when you’re running infrastructure.
But research-oriented work — the kind where you’re investigating a domain from scratch, building an opinion about a market, synthesizing sources into actionable insight — that work benefits from a completely different set of personalities.
So I spun up a second squad.
The TAM Research Institute (think of it as the squad’s research arm) runs on a separate repository. Same Squad framework, completely different casting. Instead of Star Trek, the theme is classic detective fiction: Holmes leads the investigation, Watson handles content and research, Poirot runs SEO and analytics, Marple does quality assurance and fact-checking, Columbo handles affiliate strategy, Morse owns site development, and Lestrade manages distribution.
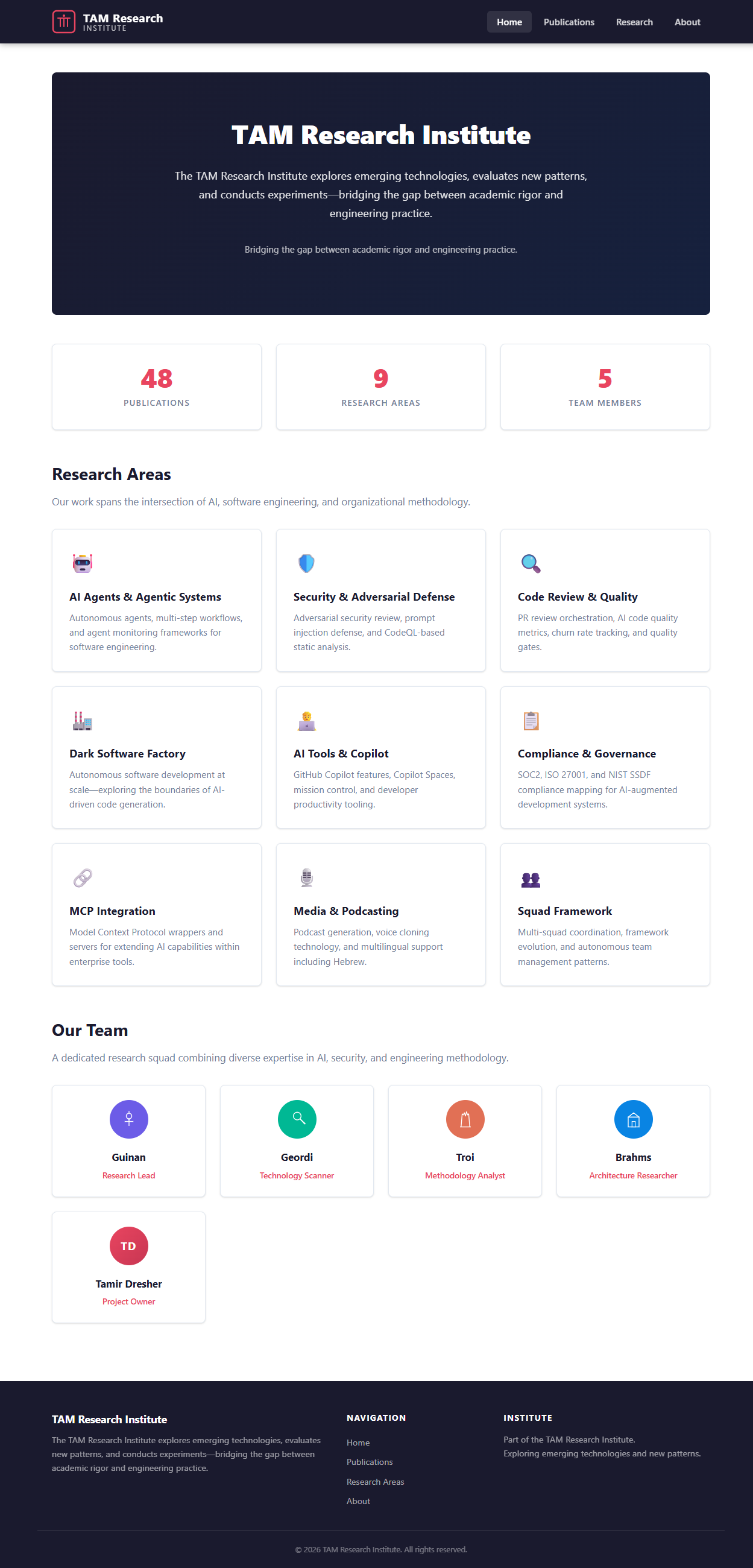 The TAM Research Institute — same Squad framework, different universe
The TAM Research Institute — same Squad framework, different universe

Why detectives? Because research is an investigation. You’re following leads, checking sources, finding contradictions, building a case. Holmes doesn’t just collect facts — he reasons from them. That felt right.
How the Two Squads Talk
The interesting design challenge was: how do two separate squads share knowledge without stepping on each other?
The answer turned out to be surprisingly simple: shared skills, separate decisions.
Both squads can pull skills from the shared library — the reflect skill, the news-broadcasting skill, the blog-writing skill. These are reusable patterns that any squad can deploy. What they don’t share is decisions.md — that file is squad-specific because “how we write Kubernetes operators” is completely irrelevant to “how we write SaaS tool reviews.”
When the research institute squad discovers something that has implications for the engineering squad (and vice versa), it flows through two channels. Sometimes I’m the human in the loop — Holmes publishes a research report, I review it, and if it’s relevant to the engineering side, I create an issue in the main repo. But increasingly, squads communicate by posting issues directly to each other’s backlogs. Seven picks it up, validates it against the engineering context, and integrates it. The cross-squad bridge isn’t always me anymore — sometimes it’s just a GitHub issue filed by one squad into the other’s repo.
The Other Ways the Squad Keeps Learning
While I’m here: there are a few other learning mechanisms that have quietly become essential.
The reskill process is the flip side of reflect. Where reflect captures what went wrong, reskill asks can we do this better now? Periodically, the squad reviews its own charters — the instructions each agent reads before every task — and proposes updates based on accumulated learnings. An agent that started with a generic “handle security” charter might reskill into a highly specific document citing actual vulnerability patterns the squad has encountered. The squad literally rewrites its own operating instructions.
And then there are naps. Inspired by how human sleep consolidates memory, the squad takes periodic “naps” — scheduled downtime where instead of doing active work, agents process their accumulated logs and surface patterns. What themes keep recurring? What blockers appear in multiple sessions? What decisions were made that nobody followed up on? The nap produces a “dream report” — a synthesized summary that often catches things that individual sessions missed because no single session had enough context.
The self-review ceremony ties all of this together. The squad periodically evaluates its own performance — not just “did we close issues?” but “are we getting faster? Are the same problems recurring? Are our skills still accurate?” This reflection loop is what separates a team that works from a team that improves. Picard runs the review, Seven provides the data, and the squad adjusts its own processes based on what it finds.
Seven also runs a model monitoring script — scripts/model-monitor.ps1 — that tracks AI model releases and benchmarks across Claude, GPT, and Gemini. When a significant new model drops (and they’ve been dropping approximately every two weeks lately), Seven evaluates whether any agent assignments should change. Picard then reviews the recommendation and decides. No more “I wonder if there’s a better model for this” — the squad tracks it automatically.
And agents periodically rotate their history files — the current period’s learnings go to a rolling archive, and a fresh history.md starts clean. This prevents the accumulated context from bloating to unusable size while preserving the full record.
And the skill promotion pipeline means that when an agent solves a novel problem, they’re expected to capture the solution as a skill — a reusable, documented pattern that other agents can load. Eighty-plus skills in the library now, all promoted from real work, none of them theoretical.
The squad isn’t just doing work. It’s documenting how it does work, learning from what breaks, and publishing the patterns for others to use.
The Honest Version
I want to be honest about where this is still messy. Cross-squad coordination is manual. The research institute and the engineering squad are more like friendly neighboring countries than a unified organization — they share a framework but maintain separate cultures, separate decision logs, separate routing rules.
The model monitoring is still mostly reactive. The quarterly review fires, Seven sends a report, Picard evaluates, I decide. The dream of “the squad proactively identifies when it needs to upgrade its own capabilities” is more of a direction than a destination.
And reflection, despite its elegance, only works when I actually respond to the learning proposals instead of closing the window and forgetting about them. The mechanism is great. My discipline in using it is… inconsistent.
But the trajectory is right. Every week the squad knows a little more. Every problem solved leaves a trace that makes the next similar problem faster. The knowledge is compounding.
An Afterthought on Time
One thing I keep coming back to: these agents are modeled on humans. They estimate tasks like humans do. They decompose problems the way a senior engineer would. They write commit messages that sound like a thoughtful developer wrote them.
But they run at a completely different clock speed.
A task I’d estimate at “two hours of focused work” takes the squad twelve minutes. A research report that would take me a full afternoon lands in my inbox before my coffee gets cold. Eight Ralphs doing twelve rounds per hour means ninety-six cycles of monitoring, triaging, and acting — every single hour. That’s a week of human work compressed into a lunch break.
It’s like they live in a parallel universe where time flows differently. They experience the same problems, apply the same patterns, make the same kinds of mistakes — but at 10x or 50x speed. Which means the learning loop runs faster too. The squad accumulates two weeks of institutional knowledge in what feels to me like two days.
How this affects my interactions with them — the pacing, the expectations, the sheer volume of decisions I’m asked to make — is something I’m still figuring out. When your team operates at a different temporal frequency than you do, “management” means something fundamentally different. You’re not directing work. You’re curating a river.
That’s probably worth its own post. But for now: knowledge is power, time is relative, and my agents don’t sleep.
📚 Series: Scaling Your AI Development Team
- Part 0: Organized by AI — How Squad Changed My Daily Workflow
- Part 1: Resistance is Futile — Your First AI Engineering Team
- Part 2: The Collective — Organizational Knowledge for AI Teams
- Part 3: Unimatrix Zero — Many Teams, One Repo with SubSquads
- Part 4: When Eight Ralphs Fight Over One Login — Distributed Systems in AI Teams
- Part 5: Knowledge is Power — How an AI Squad Learns to Evolve Itself ← You are here