“Unimatrix Zero: where individual drones regain their identity within the collective.” — Star Trek: Voyager
בחלק 2, ה-Collective נתן לנו upstream inheritance — ידע של צוות אחד שזורם לריפוים רבים. זה פתר את בעיית ה-“ריפוים רבים”. אבל השאיר את הבעיה ההפוכה בלי מענה:
מה קורה כשמספר צוותי AI צריכים לעבוד על אותו ריפו, באותו זמן?
לא שלושה סוכנים בצוות אחד. שלושה צוותים נפרדים, כל אחד אחראי על פרוסה אחרת מה-codebase, כל אחד עם ה-backlog שלו, עובדים במקביל. כמו שלושה אשכולות unimatrix של הבורג שפועלים על אותה ספינה.
הרצתי את הניסוי. זה הסיפור של מה שעבד, מה שנשבר, והפיצ’ר שצמח מתוך ההריסות.
 “לכל SubSquad יש זהות משלו, אבל כולם חלק מאותו Collective.”
“לכל SubSquad יש זהות משלו, אבל כולם חלק מאותו Collective.”
הניסוי
הריפו הוא tamirdresher/squad-tetris — משחק Tetris מרובה שחקנים שנבנה כ-monorepo:
- React frontend — לוח משחק, לובי, ממשק שחקן
- Node.js backend — שרת WebSocket, שיבוץ שחקנים, סנכרון מצב משחק
- מנוע משחק — זיהוי התנגשויות, סיבוב חלקים, ניקוד (חבילה משותפת)
- תשתית Azure — Container Apps, Cosmos DB, SignalR
יצרתי 30 issues ב-GitHub לשלושה צוותים:
| צוות | תווית | Issues | מיקוד |
|---|---|---|---|
| צוות UI | team:ui | 10 | קומפוננטות React, לוח משחק, אנימציות |
| צוות Backend | team:backend | 10 | שרת WebSocket, מצב משחק, שיבוץ שחקנים |
| צוות Cloud | team:cloud | 10 | תשתית Azure, CI/CD, ניטור |
אז הקמתי שלושה GitHub Codespaces, כל אחד עם devcontainer משלו ומשתנה סביבה SQUAD_TEAM (ראו את הקונפיגורציה בפועל):
1
2
3
4
5
6
7
8
{
"name": "Squad - UI Team",
"image": "mcr.microsoft.com/devcontainers/javascript-node:20",
"containerEnv": {
"SQUAD_TEAM": "ui-team"
},
"postCreateCommand": "npm install && squad init"
}
כל Codespace קיבל את אותו casting דטרמיניסטי של צוות (Riker כמוביל, Troi על Frontend, Geordi על Backend, Worf על טסטים, Picard על DevOps), אבל SQUAD_TEAM אמר לכל מופע על אילו issues להתמקד.
שלוש מכונות. שלושה מופעי Squad. ריפו אחד. קדימה.
מה עבד
בערך בשעתיים, 9 issues נסגרו עם קוד אמיתי ועובד:
- מנוע משחק Tetris עם זיהוי התנגשויות מלא וסיבוב חלקים (כל 7 ה-Tetrominos הסטנדרטיים)
- שרת WebSocket שמטפל בסנכרון מצב משחק מרובה שחקנים
- לוח משחק React שמרנדר גריד 10×20 עם ghost pieces ותצוגה מקדימה של החלק הבא
- CI/CD pipelines שעושים deploy ל-Azure Container Apps
branch-per-issue נשמר בעקביות. הודעות commit בפועל:
class="highlight">1
2
3
feat(game-engine): implement tetromino rotation with wall kick (#12)
feat(websocket): add room-based multiplayer with spectator mode (#18)
feat(ui): create responsive game board with CSS grid (#7)
הבידוד בין branches אפשר לשלושה צוותים לעבוד בו-זמנית בלי שה-commits היומיים שלהם יתנגשו. כל PR היה diff נקי מול main. הקוד לא היה production-ready — זה היה ניסוי — אבל מנוע המשחק באמת זיהה התנגשויות, שרת ה-WebSocket באמת טיפל בחיבורים, וקומפוננטות ה-React באמת רינדרו Tetrominos.
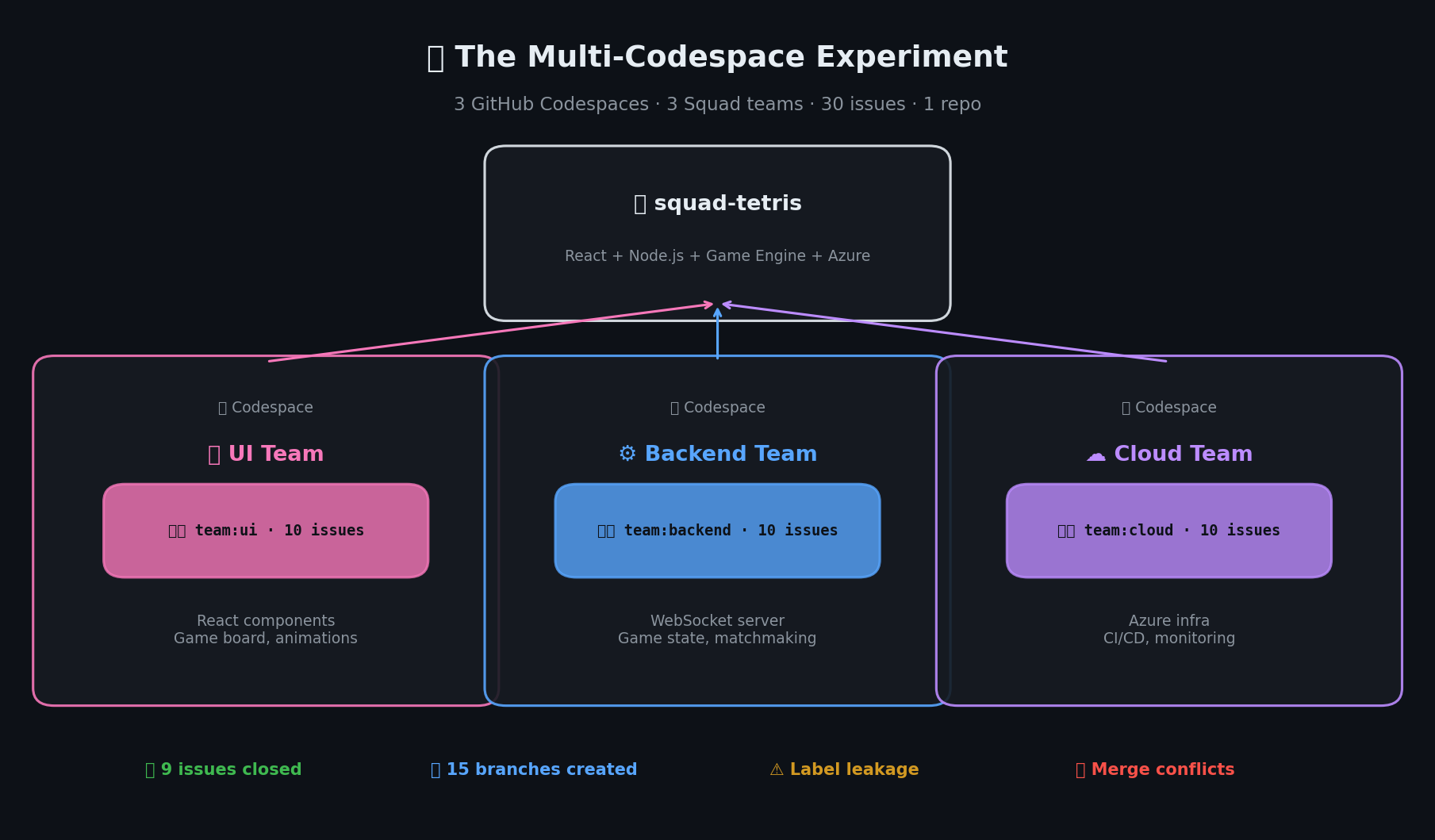 3 צוותים, 30 issues, ריפו 1 — 9 issues נסגרו בשעתיים, בתוספת לקחים קשים שנלמדו.
3 צוותים, 30 issues, ריפו 1 — 9 issues נסגרו בשעתיים, בתוספת לקחים קשים שנלמדו.
מה נשבר
ועכשיו לחלק הכנה. כי דברים ממש נשברו.
1. דליפת תוויות. צוות ה-Cloud הרים issue של UI שסומן בטעות. סוכן תשתית Azure בילה 20 דקות בניסיון לבנות קומפוננטת React. הוא הפיק PR זבל שנאלצו לסגור. מקבילה אנושית: משימת Jira שסומנה לא נכון ונחתה על board ה-sprint הלא נכון.
2. קונפליקטי merge בחבילות משותפות. גם צוות ה-UI וגם צוות ה-Backend שינו את packages/game-engine/src/types.ts באותו חלון זמן. אף סוכן לא ידע על השינויים של השני — branches מבודדים, בלי תיאום. מקבילה אנושית: בדיוק למה לצוותי monorepo יש קבצי CODEOWNERS.
3. ריבוי branches. 15 branches נוצרו, רק 6 PRs עשו merge נקי. לחלקם היו קונפליקטים. חלקם תלויים ב-branches שלא עשו merge. חלקם ננטשו באמצע הגישה. מקבילה אנושית: כל צוות בלי מדיניות ניקוי branches.
4. Codespace timeouts. idle-timeout של GitHub Codespaces הרג משימת סוכן באמצע עבודה. הסוכן חזר לקובץ שנכתב חלקית והתבלבל לגבי המצב. נאלצתי לנקות ידנית ולהתחיל מחדש פעמיים. מקבילה אנושית: הלפטופ שלך מת באמצע deploy.
5. תלויות בין-צוותיות. Issue #14 (“implement game state serialization”) תלוי ב-types מ-Issue #8 (“create tetromino type definitions”). סוכן ה-Backend התחיל לפני שסוכן ה-UI עשה merge ל-types שלו, אז הוא המציא משלו — שונים בעדינות. שני מקורות אמת לאותו מודל נתונים. מקבילה אנושית: הסיבה שקיימים ועדי סקירה ארכיטקטונית.
התובנה
הנה מה שהבנתי כשצפיתי בזה מתגלגל: כל בעיה בודדת היא בעיה שגם צוותים אנושיים נתקלים בה.
צוותי ה-AI לא נכשלו בדרכים חדשניות. הם נכשלו בדיוק באותן דרכים שצוותים אנושיים נכשלים כשמכניסים שלושה צוותים לריפו אחד בלי גדרות תיאום.
בצוותים אנושיים, פותרים את זה עם swim lanes — גבולות ברורים סביב מי אחראי על איזה קוד, אילו issues שייכים לאיזה צוות, איך תלויות בין-צוותיות מתקשרות.
בצוותי AI, צריכים את אותו דבר בדיוק. זה מה ש-SubSquads הם.
SubSquads — הפתרון
אחרי הניסוי, תרמתי לPR שהציג SubSquads — התשובה של Squad לתיאום רב-צוותי בריפו יחיד. (ייתכן שתראו את השם הישן “workstreams” בחלק מהתיעוד — זה alias שהוצא משימוש. הפקודות והמושגים זהים.)
SubSquad מוגדר ב-.squad/streams.json:
class="highlight">1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
{
"workstreams": [
{
"name": "ui-team",
"labelFilter": "team:ui",
"folderScope": ["packages/ui", "packages/game-board"],
"workflow": "default"
},
{
"name": "backend-team",
"labelFilter": "team:backend",
"folderScope": ["packages/server", "packages/game-engine"],
"workflow": "default"
},
{
"name": "cloud-team",
"labelFilter": "team:cloud",
"folderScope": ["infra/", ".github/workflows/"],
"workflow": "default"
}
]
}
כל SubSquad מגדיר שלושה דברים:
labelFilter — אילו GitHub issues הצוות הזה מרים. לא עוד דליפת תוויות. (פותר בעיה מס׳ 1.)
folderScope — באילו תיקיות הצוות הזה עובד בעיקר. ייעוצי, לא נעילה קשיחה — צוות ה-backend עדיין יכול לקרוא מ-packages/ui כדי להבין ממשקים. אבל כשיוצרים קבצים, סוכנים מעדיפים את התיקיות שב-scope שלהם. (מפחית בעיה מס׳ 2 — קונפליקטים בקוד משותף.)
workflow — איזה workflow של טקסים וקבלת החלטות להשתמש בו. צוותים שונים יכולים לקבוע דרישות review או שערי deployment שונים.
מפעילים SubSquad עם:
class="highlight">1
squad subsquads activate ui-team
או לרשום ולבדוק סטטוס:
class="highlight">1
2
squad subsquads list
squad subsquads status
זיהוי אוטומטי דרך משתנה הסביבה SQUAD_TEAM אומר שלא צריכים להפעיל ידנית. מגדירים SQUAD_TEAM=ui-team ב-devcontainer של ה-Codespace, ו-Squad מפעיל את ה-SubSquad הנכון אוטומטית. (פותר בעיה מס׳ 3 — branches מקבלים קידומת צוות כמו ui-team/issue-7-game-board, מה שהופך את הבעלות והניקוי לברורים.)
 כל SubSquad מקבל swim lane משלו: מסנני תוויות, folder scopes, ו-branches עם קידומת שומרים על צוותים מבודדים.
כל SubSquad מקבל swim lane משלו: מסנני תוויות, folder scopes, ו-branches עם קידומת שומרים על צוותים מבודדים.
התמונה המלאה
במבט לאחור על סדרת שלושת החלקים הזו, קשת ה-scaling ברורה:
צוות אחד, ריפו אחד (חלק 1) — Squad נותן לכם צוות AI מתואם שעובד במקביל. Riker מוביל, סוכנים מתמחים, Ralph מנטר.
צוות אחד, ריפוים רבים (חלק 2) — upstream inheritance מחבר צוותים מבודדים ל-Collective. ידע זורם למעלה, החלטות זורמות למטה.
צוותים מרובים, ריפו אחד (הפוסט הזה) — SubSquads נותנים לכל צוות swim lane בתוך codebase משותף. סינון תוויות, folder scoping, ו-branch-per-issue שומרים על צוותים מלדרוך אחד לשני על הרגליים.
ביחד, אלה מאפשרים לכם לעשות scale מ-“מפתח אחד שמנסה Squad” ל-“מספר צוותי AI לרוחב מספר ריפוים” — אותו framework, אותו בסיס של Copilot CLI, אותה מערכת casting בסגנון בורג.
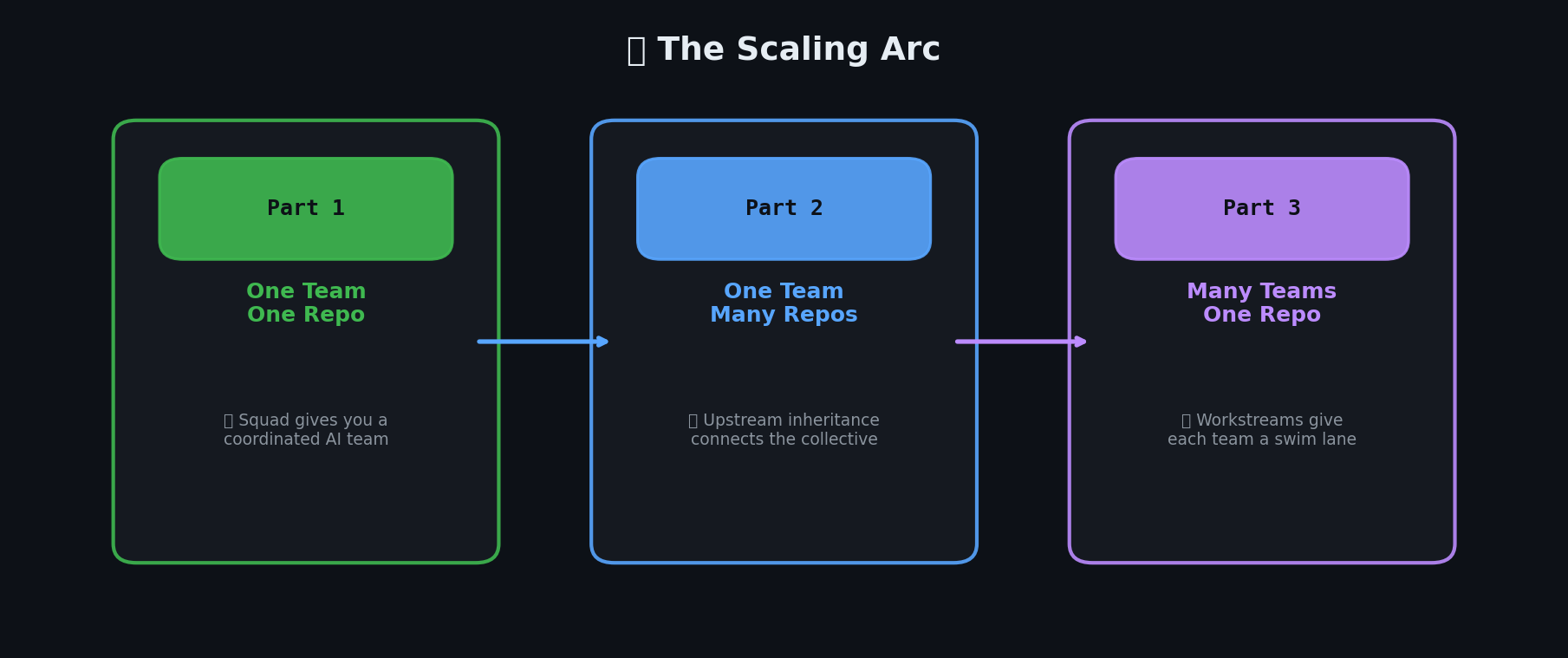 קשת ה-scaling בשלושה חלקים: מצוות אחד בריפו אחד, לידע משותף בין ריפוים, לצוותים מרובים בריפו אחד.
קשת ה-scaling בשלושה חלקים: מצוות אחד בריפו אחד, לידע משותף בין ריפוים, לצוותים מרובים בריפו אחד.
תיאום רב-מכונות — Ralph בכל מקום
SubSquads פתרו עבודה מקבילית בתוך מכונה אחת. אבל הנה העניין — אני לא עובד על מכונה אחת.
יש לי את הלפטופ עבודה. Cloud PC dev box. דסקטופ בבית. Ralph רץ על כל אחד מהם. שלושה Ralphs, שלוש מכונות, ריפו אחד. איך הם לא דורכים אחד לשני על הרגליים?
תור המשימות המבוזר (זה פשוט Git)
בנינו מערכת משימות מבוזרת. שכבת התעבורה? Git. פורמט ההודעות? YAML. תהליך ה-worker? Ralph.
זה לא Kafka. זה git pull && scan && do && git push. ובכנות? לצוות AI של סוכנים לרוחב מכונות, זה עובד טוב באופן מפתיע.
המבנה חי ב-.squad/cross-machine/:
class="highlight">1
2
3
4
5
6
7
.squad/cross-machine/
├── config.json # Per-machine settings
├── tasks/ # Task queue (YAML files)
│ ├── blog-part3-review.yaml
│ └── sample-test-task.yaml
└── responses/ # Machine responses
└── blog-part3-CPC-tamir-WCBED.md
קובץ משימה נראה ככה — לא צריך message brokers:
class="highlight">1
2
3
4
5
6
7
8
9
10
11
id: blog-part3-whats-next-section
source_machine: production-main
target_machine: ANY
priority: high
created_at: 2026-03-15T14:08:00Z
task_type: review
description: "Add 'What's Next' section (~200 words) to blog Part 3"
payload:
command: "echo 'Read blog-part2-refresh.md, write 200-word What's Next...'"
expected_duration_min: 30
status: completed
לכל מכונה יש config.json שמצהיר מי היא:
class="highlight">1
2
3
4
5
6
7
8
9
10
11
{
"enabled": true,
"poll_interval_seconds": 300,
"this_machine_aliases": ["TAMIRDRESHER", "CPC-tamir-WCBED"],
"max_concurrent_tasks": 2,
"task_timeout_minutes": 60,
"command_whitelist_patterns": [
"python scripts/*", "node scripts/*", "pwsh scripts/*",
"gh *", "git *", "echo *"
]
}
כן, יש command whitelist. Worf היה מתעקש. לא נותנים לקובץ YAML ממכונה אחרת להריץ קוד שרירותי על שלכם.
scripts/cross-machine-watcher.ps1 הוא המנוע. הוא עושה polling כל 5 דקות, מושך משימות חדשות, בודק אם target_machine מתאים (או שהוא ANY), מאמת את הפקודה מול ה-whitelist, מריץ, ודוחף את התוצאה בחזרה. Git pull לפני סריקה, git push אחרי תגובה. זה כל הפרוטוקול.
Mutex ובעלות
על מכונה בודדת, Ralph משתמש ב-named mutex ברמת המערכת כדי למנוע כפילויות:
class="highlight">1
2
3
4
5
6
7
$mutexName = "Global\RalphWatch_tamresearch1"
$mutex = New-Object System.Threading.Mutex($false, $mutexName)
$acquired = $mutex.WaitOne(0)
if (-not $acquired) {
Write-Host "Another Ralph is already running on this machine" -ForegroundColor Red
exit 1
}
בין מכונות, ה-YAML של המשימה עצמו הוא הנעילה. Ralph תובע משימה על ידי עדכון ה-status מ-pending ל-executing, הוספת שם המכונה שלו, ודחיפה. אם שני Ralphs מתחרים, merge conflict של git הוא השובר שוויון. לא אלגנטי. אפקטיבי.
שמות branches כוללים $env:COMPUTERNAME כדי שתוכלו לעקוב אחרי איזו מכונה עשתה מה: squad/591-voice-cloning-LAPTOP מול squad/591-voice-cloning-DEVBOX-GPU. כשללפטופ שלי אין GPU ול-DevBox יש, ה-Squad של הלפטופ יוצר משימת cross-machine ל-voice cloning inference. Ralph על ה-DevBox מרים אותה, מריץ את המודל, דוחף את התוצאה. שתי מכונות, workflow אחד, אפס תיאום ידני.
סיפור ה-Debugging (או: הבאג הכי קשה היה סיומת קובץ)
השתמשתי במערכת הזו לפוסט הזה עצמו. דחפתי משימה שביקשה מכל המכונות לתרום סעיף “מה הלאה”. מכונת ה-CPC הגיבה תוך שעה. המכונות האחרות? שקט רדיו.
אז חפרתי ומצאתי ארבעה באגים. קובץ המשימה נשמר כ-.md אבל ה-watcher סרק רק *.yaml — המערכת המבוזרת עבדה מושלם, היא פשוט לא ראתה את המשימה. הבדיקה של cross-machine הייתה קיימת בקוד של Ralph אבל הפונקציה הוגדרה ואף פעם לא נקראה. ל-config היו כינויי מכונה שלא התאימו ל-$env:COMPUTERNAME. וה-watcher אף פעם לא הריץ git pull לפני הסריקה — משימות חדשות היו בלתי נראות עד שמישהו עשה pull ידנית.
בנינו תור עבודה מבוזר עם eventual consistency על פני שלוש מכונות פיזיות. הבאג הכי קשה היה סיומת קובץ. הייתי אומר שהבעיה האמיתית של מערכות מבוזרות היא DNS, אבל במקרה שלנו זה היה YAML. למה הסוכן לא הרים את המשימה? כי הייתה לו בעיית commitment — ספציפית, commitment ל-.md כשהיה צריך .yaml.
כל מהנדס בכיר שקורא את זה מהנהן. התיאוריה קלה. התשתית המשעממת — סיומות קבצים, ברירות מחדל של קונפיגורציה, קוד אינטגרציה שאף פעם לא חובר — שם חיה העבודה האמיתית.
מה הלאה
SubSquads פתרו תיאום רב-צוותי. משימות cross-machine פתרו תיאום רב-מכשירי. אבל הניסוי חשף שאלות שמצביעות הרבה יותר רחוק קדימה.
Squad Mesh — squads מדברים עם squads. ה-Squad שלי חי ב-tamresearch1. לצוות שלי במיקרוסופט יש שנים-עשר ריפוים. לצוותים אחרים יש Squads משלהם. מה קורה כשה-Squads האלה צריכים לשתף פעולה? דמיינו שה-Squad של Picard מזהה שינוי ב-Helm chart ב-dk8s-platform ששובר חוזה API ש-dk8s-operators תלוי בו. היום, Picard פותח issue ובן אדם מתאם. מחר? ה-Squad של Picard מדבר ישירות עם ה-Squad של הריפו השני. המוביל שלהם מפרק את התיקון, מקצה את המומחים שלהם. שני Squads, שני ריפוים, אפס בני אדם בלולאת ההעברה. לבורג היו קישורי subspace. גם לנו יהיו.
מתאם-על — מתאם של מתאמים — יכול לצפות בכל ה-SubSquads, לזהות תלויות בין-צוותיות כמו הקונפליקט של types.ts, ולפתור אותן לפני שהן קורות. חשבו על Borg Queen, אבל מועילה. זיהוי תלויות בין SubSquads יכול לסדר issues נכון כשעבודה של צוות אחד חוסמת צוות אחר.
שוק ה-Skills. בחלק 1, סוכנים מפתחים skills — דפוסים לשימוש חוזר שנלכדים מעבודה אמיתית. זה העברת ידע בתוך ה-squad. הצעד הבא הוא העברה בין squads. שוק שבו Squads מפרסמים דפוסים מוכחים: “ככה אנחנו מטפלים בסריקת תאימות FedRAMP” או “זו אסטרטגיית הטסטים שלנו ל-Kubernetes operators.” Squads אחרים נרשמים. כש-skill מתעדכן — נגיד, גישה חדשה לסריקת CVE — כל Squad שנרשם מקבל את העדכון אוטומטית. Skills לא רק נשמרים. הם מתפשטים.
Seven כמכון מחקר. התפקיד של Seven מתפתח מסוכנת תיעוד למודעות סביבתית רציפה. סורק חדשות טכנולוגיות יומי שמנטר HackerNews, Reddit ו-X לחיפוש התפתחויות רלוונטיות. אבל זה הולך רחוק יותר — Seven לא רק מדווחת חדשות, היא מעריכה אותן מול היכולות הנוכחיות של ה-Squad שלכם. “מודל חדש שוחרר שמהיר פי 3 ב-code review — הנה benchmark מול ההגדרה הנוכחית שלנו.” או: “CVE פורסם שמשפיע על תלות בשלושה מהריפוים שלנו — הנה ניתוח ההשפעה, כבר בתור עבור Worf.”
סקייל ארגוני. ריפו אישי → ריפו צוותי → Squad Mesh → ארגון. Squads בכל שכבה. צוותי מוצר, צוותי פלטפורמה, צוותי אבטחה, צוותי SRE — כל אחד עם סוכנים מתמחים. מחוברים דרך mesh שמשתף skills רלוונטיים ומתאם עבודה חוצת-תחומים. יחידת אימוץ ה-AI היא לא המודל. היא לא ה-prompt. היא אפילו לא הסוכן. היא ה-squad.
התחלנו עם אדם אחד וסקריפט watch. אנחנו בדרך לאינטליגנציה ארגונית שמצטברת על פני כל צוות, כל ריפו, כל sprint.
ה-Borg Collective טמעו ציוויליזציות שלמות. ה-Squad Collective שלכם יכול לטמע את ה-backlog שלכם. ההבדל הוא שהמפתחים שלכם שומרים על האינדיבידואליות שלהם.
ההתנגדות חסרת תועלת — אבל שיתוף פעולה הוא אופציונלי. בחרו בחוכמה. 🟩⬛
בדקו את ריפו הניסוי squad-tetris כדי לראות את הקוד, ה-issues, וה-PRs בפועל מניסוי ה-multi-Codespace.
📚 Series: Scaling AI-Native Software Engineering
- חלק 0: מאורגן על ידי AI — איך Squad שינה את שגרת העבודה היומית שלי
- חלק 1: ההתנגדות חסרת תועלת — צוות הנדסת AI הראשון שלך בעבודה
- חלק 2: הקולקטיב — ידע ארגוני לצוותי AI
- חלק 3: Unimatrix Zero — צוותים מרובים, ריפו אחד עם SubSquads ← אתם כאן
- חלק 4: כששמונה ראלפים נלחמים על לוגין אחד — מערכות מבוזרות בצוותי AI