“We are the Borg. We will add your technological distinctiveness to our own.” — The Borg, Star Trek: The Next Generation
בחלק 1, הקמתי את ה-Squad הראשון שלי על פרויקט פנימי שנקרא provisioning wizard — עם צוות בסגנון Matrix: Morpheus, Trinity, Switch, Dozer (Star Trek כבר היה תפוס בריפו האישי שלי) — וצפיתי בהם טוחנים 52 משימות Planner במקביל. מדהים. ואז עשיתי מה שכל מהנדס נלהב עושה: הקמתי Squad על ריפו שני.
והצוות השני לא ידע שום דבר שהצוות הראשון למד.
Trinity ב-provisioning wizard כבר הבינה את פורמט ה-PR שלנו, את מוסכמות התיעוד שלנו, את דפוסי השילוב של MCP. הסוכנים ב-ConfigurationGeneration — אותו ארגון, אותו צוות — הסתכלו עליי עם פרצוף של סימן שאלה כשהזכרתי משהו מכל זה. כל Squad של ריפו היה אי בודד. דרון מנותק בלי Collective.
ואז נפל לי האסימון: הבעיה הקשה באמת ב-scaling של צוותי AI היא לא לגרום להם לעבוד בריפו אחד. האתגר האמיתי הוא לגרום להם לשתף ידע כמו שארגון הנדסי אמיתי עושה.
 “נוסיף את הייחודיות הארגונית שלכם לשלנו.”
“נוסיף את הייחודיות הארגונית שלכם לשלנו.”
המבנה האמיתי של ארגוני תוכנה
רוב ארגוני ההנדסה האמיתיים לא חיים ב-monorepo. יש להם שכבות:
- ארגון — תקני ארכיטקטורה, מוסכמות קוד, מדיניות אבטחה. “כל השירותים משתמשים ב-managed identity.” “OpenAPI spec לכל API.”
- צוות — מומחיות תחומית שחוצה מספר ריפוים. “ה-.NET SDKs שלנו עוקבים אחרי הדפוס הזה.” “ADRs נמצאים ב-
docs/decisions/.” - ריפו — פרטי מימוש. קבצי ההקשר הספציפיים, ההחלטות המקומיות, המוזרויות של הריפו הספציפי.
כל רמה מייצרת ידע שצריך לזרום למטה. תקני ארכיטקטורה הם אוניברסליים. מומחיות תחומית היא ברמת הצוות. פרטי מימוש הם ספציפיים לריפו. זה לא overhead — ככה ארגוני הנדסה באמת עובדים.
כשמקימים Squad על כל ריפו, כל צוות מקבל את ה-AI squad שלו. אבל בלי הקשר משותף, ה-squads האלה הם דרונים בלי Collective.
הבעיה: ידע בהעתק-הדבק
הנה מה שבאמת קרה לי. בזבזתי שבועות על לבנות הקשר ב-ConfigurationGeneration — .NET SDK שמייצר deployment artifacts. יש לו .roo/context/ עם 8 קבצי הקשר שמכסים הכל — מארכיטקטורת ה-SDK ועד דפוסי ה-deployment. יש לו docs/decisions/ עם 70+ ADRs. יש לו docs/designs/ עם מסמכי עיצוב מפורטים. הסוכנים שעובדים בריפו הזה יודעים דברים. הם מכירים מוסכמות שמות, דפוסי טיפול בשגיאות, מבנה טסטים — הכל.
אז פתחתי את הריפו של provisioning wizard. ריפו אחר, אותו צוות. התחלתי סשן Squad חדש. לסוכנים שם היה .squad/skills/ משלהם עם 3 skills משותפים — docs-hygiene, fabric-rti-mcp, ו-pr-format. אבל הם לא ידעו שום דבר על הדפוסים הארגוניים שתיעדתי בקפידה ב-ConfigurationGeneration.
מצאתי את עצמי חוזר על עצמי שוב ושוב. כל ריפו חדש, כל Squad חדש — אותן מוסכמות מההתחלה. זה המקבילה ב-AI לתקני קוד בוויקי שאף אחד לא קורא.
ירושת Upstream
הפתרון של Squad הוא upstream inheritance — מערכת ידע היררכית שמשקפת איך ארגונים אמיתיים עובדים. לכל ריפו יש תיקיית .squad/ משלו, ומחברים ריפוים למקורות ידע משותפים דרך squad upstream add:
1
2
3
4
# In your repo:
squad init
squad upstream add https://github.com/my-org/platform-squad.git --name org
squad upstream add https://github.com/my-org/my-team-squad.git --name team
זה יוצר היררכיה:
class="highlight">1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
my-org/platform-squad.git ← Org level (a regular repo with .squad/)
.squad/
decisions.md ← "Always use managed identity"
"APIs follow OpenAPI spec"
skills/ ← Shared patterns: error handling,
logging, API conventions
routing.md ← Default routing rules
my-org/my-team-squad.git ← Team level (another repo with .squad/)
.squad/
decisions.md ← "ADRs in docs/decisions/"
".NET SDK naming conventions"
skills/ ← Team-specific patterns
my-repo/.squad/ ← Repo level
decisions.md ← Repo-specific decisions
agents/ ← This repo's team
כש-Squad מתחיל סשן, הוא קורא את ההקשר של .squad/ של הריפו עצמו, ואז קורא כל upstream בסדר. סוכן שעובד בריפו שלכם יודע על מדיניות ארגונית, מוסכמות צוותיות, והחלטות ספציפיות לריפו — הכל בלי שתגידו מילה.
מודל הפתרון הוא closest-wins: ההקשר של הריפו עצמו תמיד מקבל עדיפות. אם הארגון אומר “TypeScript לכל השירותים החדשים” אבל הריפו שלכם הוא כלי Go CLI, ההחלטה ברמת הריפו דורסת את ההחלטה ברמת הארגון — לריפו הזה בלבד. ברירות מחדל ארגוניות עדיין חלות בכל מקום אחר.
החלטות זורמות למטה. דריסות הן מקומיות. מקבלים עקביות ארגונית עם אוטונומיה ברמת הצוות.
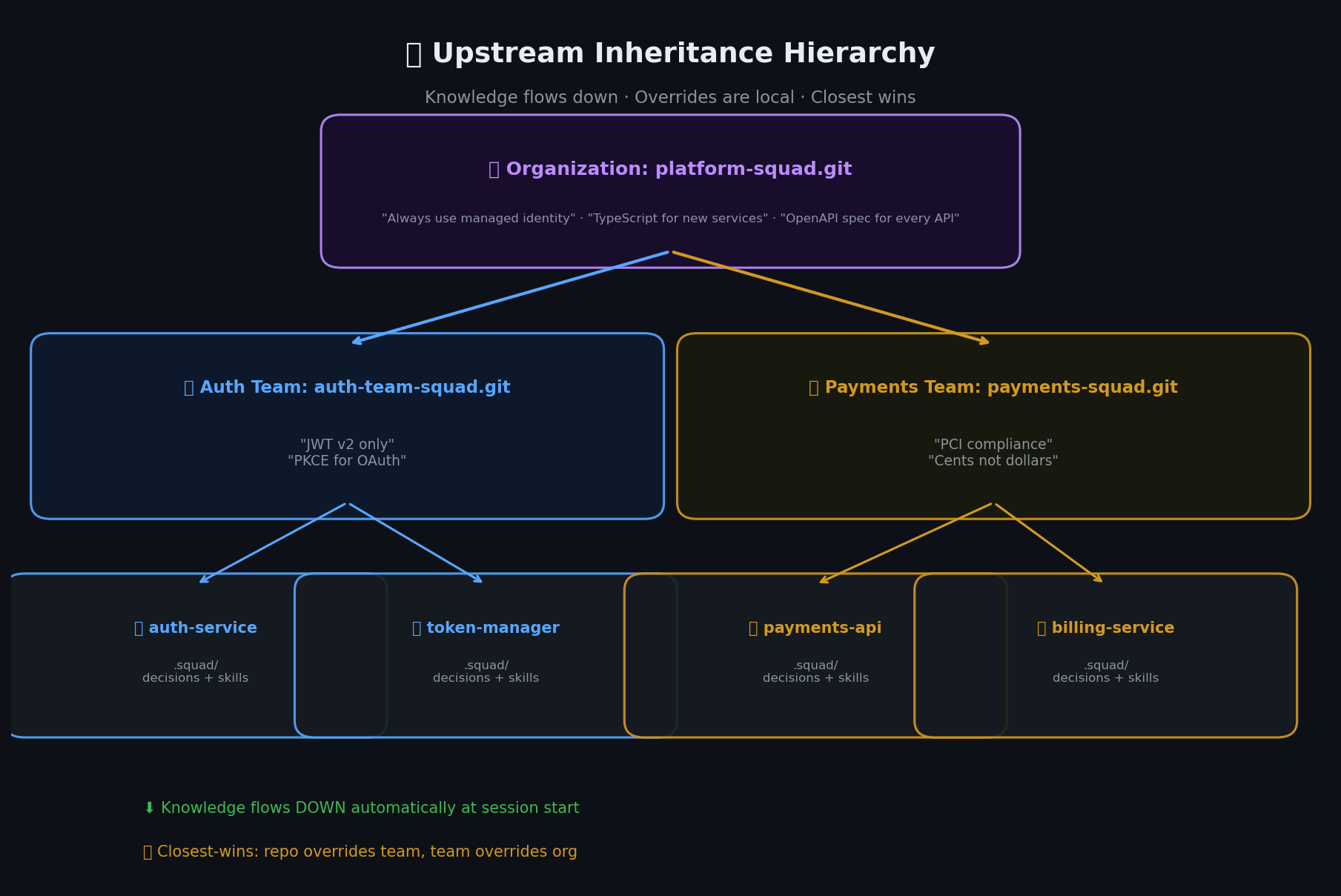 הידע זורם למטה דרך ההיררכיה: ארגון → צוות → ריפו. כל רמה יכולה לדרוס עם פתרון closest-wins.
הידע זורם למטה דרך ההיררכיה: ארגון → צוות → ריפו. כל רמה יכולה לדרוס עם פתרון closest-wins.
חיבור ריפו ל-Upstream שלו
upstream inheritance לא אוטומטי. כשמריצים squad init בריפו חדש, Squad לא יודע באופן קסום לאן להסתכל. אתם אומרים לו:
class="highlight">1
2
3
4
5
# Git repository — cloned and cached locally
squad upstream add https://github.com/my-org/platform-squad.git --name org
# Local directory — read live at session start
squad upstream add ../org-practices/.squad --name org-local
מנהלים upstreams עם סט קטן של פקודות:
class="highlight">1
2
3
4
squad upstream list # See what's connected
squad upstream remove org # Disconnect an upstream
squad upstream sync # Update all git-based upstreams
squad upstream sync org # Update a specific upstream
מתחת למכסה המנוע: Git upstreams נשכפלים ל-.squad/_upstream_repos/{name} (ב-gitignore). הם מתעדכנים כשמריצים squad upstream sync. upstreams מקומיים נקראים בזמן אמת — משנים את המקור, והסשן הבא מרים את השינוי.
בכל התחלת סשן: Squad טוען את ה-.squad/ של הריפו, ואז קורא כל upstream לפי סדר וממזג עם closest-wins. הריפו תמיד מנצח.
הזרימה היא חד-כיוונית: upstream זורם למטה. סוכנים בריפו יכולים לקרוא החלטות ו-skills מ-upstream, אבל הם אף פעם לא כותבים חזרה. אם סוכן מגלה דפוס מצוין ואתם רוצים שכל הצוות ייהנה ממנו, מייצאים אותו ותורמים אותו חזרה ידנית:
class="highlight">1
2
3
4
5
# Export a skill from this repo
squad export --skill azure-keyvault-identity -o keyvault-skill.json
# Then add the exported skill to the team's upstream repo
# (commit it there so every downstream repo picks it up on next sync)
זה מכוון. ידע upstream הוא מאוצר, לא crowdsourced. קידום הוא החלטה מודעת — כמו code review לידע ארגוני.
מה משותף (ומה לא)
משותף דרך upstream לא משותף החלטות — מדיניות, מוסכמות, עקרונות ארכיטקטוניים זהויות סוכנים — כל ריפו מגייס את הצוות שלו Skills — דפוסים לשימוש חוזר עם רמות ביטחון היסטוריה — היסטוריית שיחות נשארת לפי ריפו חוכמה — הקשר מצטבר ולקחים שנלמדו לוגים של אורקסטרציה — מצב משימות, ארטיפקטים של סשן מדיניות גיוס — צורות ותפקידי צוות ברירת מחדל כללי ניתוב — דפוסי חלוקת עבודה
תחשבו על זה כמו הבורג: לדרונים בודדים יש חומרה משלהם ומצב משימה מקומי. ה-Collective משתף הנחיות, טקטיקות וידע מצטבר. אף דרון לא צריך לדעת מה דרון אחר אכל לארוחת בוקר.
Skills ומחזור חיי הביטחון
כאן האנלוגיה של ה-Collective נהיית אמיתית.
סוכן מגלה דפוס — נגיד, הדרך הנכונה לפרמט PRs לתהליך ה-code review של הצוות. הוא שומר את זה כ-skill: דפוס לשימוש חוזר עם שלבים, הקשר, ומטאדאטה של ביטחון.
ל-skills יש מחזור חיי ביטחון:
- Low — תצפית אחת, ריפו אחד. הדפוס עובד כאן אבל לא אומת במקומות אחרים.
- Medium — שימוש מוצלח במספר הקשרים. נראה כמו דפוס אמיתי, לא חד-פעמי.
- High — אומת בין ריפוים, נבדק על ידי בני אדם. זו פרקטיקה מבוססת.
יש לי דוגמה אמיתית לזה. בריפו של provisioning wizard, בתיקיית .squad/skills/ יש skill בשם pr-format. הוא מגדיר בדיוק איך PRs צריכים להיות מובנים — פורמט כותרת, חלקי תיאור, פריטי checklist. אחרי שימוש במספר PRs ואימות על ידי הצוות, הוא הגיע ל-confidence: high:
class="highlight">1
2
3
4
5
6
7
8
# .squad/skills/pr-format/skill.yml
name: pr-format
description: Standard PR format for team repos
confidence: high
steps:
- title follows conventional commits format
- description includes context, changes, and testing sections
- checklist includes review items for security, docs, tests
ה-confidence: high הזה אומר שה-skill הזה עבר מבחן קרב. הוא התחיל כתצפית עם ביטחון נמוך — “נראה שפורמט ה-PR הזה עובד טוב” — והתקדם דרך שימוש ואימות אנושי.
ברגע ש-skill מגיע לביטחון גבוה, מקדמים אותו. מייצאים אותו מהריפו, עושים commit ל-upstream של הצוות. כל ריפו שמחובר ל-upstream הזה מרים אותו ב-squad upstream sync הבא. כל ריפו חדש שהצוות יוצר צריך רק פקודת squad upstream add אחת והדפוס שם מהיום הראשון.
Skills זורמים למעלה ידנית (export → commit ל-upstream) אבל זורמים למטה אוטומטית (נקראים בהתחלת סשן). ה-Collective לומד. ההתאמה של דרון אחד הופכת ליתרון של כולם.
 Skills מתבגרים מגילוי לאימוץ ארגוני: ביטחון low → medium → high, ואז מקודמים ל-upstream.
Skills מתבגרים מגילוי לאימוץ ארגוני: ביטחון low → medium → high, ואז מקודמים ל-upstream.
דוגמה אמיתית: ConfigurationGeneration + Provisioning Wizard
בואו אעבור על התרחיש האמיתי שלי.
ConfigurationGeneration הוא ה-.NET SDK שלנו ליצירת ארטיפקטים של פריסה. לאורך חודשים של עבודה עם Squad, הריפו הזה צבר ידע ארגוני רציני:
.roo/context/ — 8 קבצי הקשר שמכסים את ארכיטקטורת ה-SDK, דפוסי deployment, מוסכמות שמות, טיפול בשגיאות ומבנה טסטיםdocs/decisions/ — 70+ רשומות החלטות ארכיטקטוניות (ADR) שמתעדות למה בחרנו בדפוסים ספציפייםdocs/designs/ — מסמכי עיצוב לפיצ’רים מרכזיים
זה הרבה ידע. ורובו לא ספציפי לריפו — הוא ברמת הצוות או אפילו ברמת הארגון. דברים כמו “ADRs נמצאים ב-docs/decisions/”, “להשתמש בדפוס טיפול בשגיאות הזה”, “תיאורי PR עוקבים אחרי הפורמט הזה” — אלה חלים על כל ריפו שהצוות מחזיק.
Provisioning wizard הוא כלי ה-provisioning הפנימי שלנו. יש לו .squad/skills/ משלו עם 3 skills (docs-hygiene, fabric-rti-mcp, pr-format). תחום שונה, אבל אותן מוסכמות צוות.
לפני upstream inheritance, הקמת Squad על ריפו חדש דרשה:
- העתקה ידנית של קבצי ההקשר הרלוונטיים
- הסבר מחדש של מוסכמות ארגוניות
- לקוות שלא פספסתם שום דבר
- לחזור על הכל לריפו הבא
עם upstream inheritance, זה שתי פקודות:
class="highlight">1
2
squad init
squad upstream add https://github.com/my-org/my-team-squad.git --name team
סיימנו. ריפו ה-upstream ברמת הצוות מכיל את הידע הארגוני המזוקק — המוסכמות מקבצי ההקשר של ConfigurationGeneration, ה-skills המאומתים מ-provisioning wizard, תבניות ה-ADR, פורמט ה-PR. כל ריפו חדש שהצוות יוצר יורש את כל זה מהרגע הראשון.
70+ ה-ADRs נשארים ב-ConfigurationGeneration (אלה החלטות מימוש ספציפיות לריפו). אבל הדפוס — “אנחנו כותבים ADRs, הנה התבנית, הנה לאן הם הולכים” — זה חי ב-upstream של הצוות. ה-skill של pr-format עם confidence: high מ-provisioning wizard? כבר ב-upstream. מוסכמות הטיפול בשגיאות מקבצי ההקשר של ConfigurationGeneration? חולצו ונעשה להם commit ל-upstream של הצוות.
הקמת ריפו חדש עברה משעות של בניית הקשר ידנית לשתי פקודות ו-squad upstream sync. פשוט ככה.
מה הלאה
upstream inheritance פותר את בעיית הידע הארגוני. צוותי ה-AI שלכם משתפים הקשר כמו שארגוני הנדסה אמיתיים עובדים — באופן היררכי, מכוון, עם אוטונומיה מקומית ועקביות גלובלית.
אנחנו גם עובדים על להפוך את ה-upstream לדינמי יותר ומסונכרן אוטומטית — בדיוק כמו שצוותים אנושיים רגילים עובדים. היום מריצים squad upstream sync ידנית, אבל החזון הוא סנכרון רציף שבו ידע upstream זורם לריפוים downstream אוטומטית, ושומר על כל Squad בארגון מעודכן בלי התערבות אנושית.
אבל יש אתגר הרחבה נוסף שלא התייחסתי אליו:
מה קורה כשמספר צוותים צריכים לעבוד על אותו ריפו בו-זמנית?
כרגע, Squad אחד לריפו עובד מצוין. אבל מה אם צריכים workstream של frontend, workstream של backend, ו-workstream של תשתיות — כולם באותו codebase, כולם רצים במקביל? אם מקימים שלושה סשנים של Squad, האם הם ידרכו אחד לשני על הרגליים? האם merge conflicts יהרסו הכל?
בחלק 3: “Unimatrix Zero”, אראה לכם SubSquads — איך מריצים מספר צוותי AI על ריפו אחד עם workstreams מבודדים. מה עבד, מה נשבר, ולמה זה נשבר בצורה מרהיבה לפני שזה עבד יפה. 🟩⬛
📚 Series: Scaling AI-Native Software Engineering
- חלק 0: מאורגן על ידי AI — איך Squad שינה את שגרת העבודה היומית שלי
- חלק 1: ההתנגדות חסרת תועלת — צוות הנדסת AI הראשון שלך בעבודה
- חלק 2: הקולקטיב — ידע ארגוני לצוותי AI ← אתם כאן
- חלק 3: Unimatrix Zero — צוותים מרובים, ריפו אחד עם SubSquads
- חלק 4: כששמונה ראלפים נלחמים על לוגין אחד — מערכות מבוזרות בצוותי AI